Microsoft SQL Server Training Classes in Idaho Falls, Idaho
Learn Microsoft SQL Server in Idaho Falls, Idaho and surrounding areas via our hands-on, expert led courses. All of our classes either are offered on an onsite, online or public instructor led basis. Here is a list of our current Microsoft SQL Server related training offerings in Idaho Falls, Idaho: Microsoft SQL Server Training
Microsoft SQL Server Training Catalog
Course Directory [training on all levels]
- .NET Classes
- Agile/Scrum Classes
- AI Classes
- Ajax Classes
- Android and iPhone Programming Classes
- Azure Classes
- Blaze Advisor Classes
- C Programming Classes
- C# Programming Classes
- C++ Programming Classes
- Cisco Classes
- Cloud Classes
- CompTIA Classes
- Crystal Reports Classes
- Data Classes
- Design Patterns Classes
- DevOps Classes
- Foundations of Web Design & Web Authoring Classes
- Git, Jira, Wicket, Gradle, Tableau Classes
- IBM Classes
- Java Programming Classes
- JBoss Administration Classes
- JUnit, TDD, CPTC, Web Penetration Classes
- Linux Unix Classes
- Machine Learning Classes
- Microsoft Classes
- Microsoft Development Classes
- Microsoft SQL Server Classes
- Microsoft Team Foundation Server Classes
- Microsoft Windows Server Classes
- Oracle, MySQL, Cassandra, Hadoop Database Classes
- Perl Programming Classes
- Python Programming Classes
- Ruby Programming Classes
- SAS Classes
- Security Classes
- SharePoint Classes
- SOA Classes
- Tcl, Awk, Bash, Shell Classes
- UML Classes
- VMWare Classes
- Web Development Classes
- Web Services Classes
- Weblogic Administration Classes
- XML Classes
- Enterprise Linux System Administration
21 September, 2026 - 25 September, 2026 - RED HAT ENTERPRISE LINUX AUTOMATION WITH ANSIBLE
9 November, 2026 - 12 November, 2026 - OPENSHIFT ADMINISTRATION
19 October, 2026 - 21 October, 2026 - KUBERNETES ADMINISTRATION
24 August, 2026 - 26 August, 2026 - Linux Troubleshooting
31 August, 2026 - 4 September, 2026 - See our complete public course listing
Blog Entries publications that: entertain, make you think, offer insight
Creating an enum in Python prior to Python 3.4 was accomplished as follows:
def enum(**enums)::
return type('Enum',(),enums)
then use as:
Animals=enum(Dog=1,Cat=2)
and accessed as:
Animals.Dog
The new version can be created as follows:
from enum import Enum
class Animal(Enum):
Dog=1
Cat=2
Information Technology is one of the most dynamic industries with new technologies surfacing frequently. In such a scenario, it can get intimidating for information technology professionals at all levels to keep abreast of the latest technology innovations worth investing time and resources into.
It can therefore get daunting for entry and mid-level IT professionals to decide which technologies they should potentially be developing skills. However, the biggest challenge comes for senior information technology professionals responsible for driving the IT strategy in their organizations.
It is therefore important to keep abreast of the latest technology trends and get them from reputable sources. Here are some of the ways to keep on top of the latest trends in Information Technology.
· Subscribe to leading Analyst Firms: If you work for a leading IT organization, chances are that you already have subscription to leading IT analyst firms notably Gartner and Forrester. These two firms are some of the most recognized analyst firms with extensive coverage on almost every enterprise technology including hardware and software. These Analyst firms frequently publish reports on global IT spending and trends that are based on primary research conducted on vendors and global CIOs & CTOs. However, subscription to these reports is very expensive and if you are a part of a small organization you may have issues securing access to these reports. One of the most important pieces of research published by these firms happens to be the Gartner Hype Cycle which plots leading technologies and their maturity curve.Even if you do not have access to Gartner research, you can hack your way by searching for “Gartner Hype Cycle” on Google Images and you will in most cases be able to see the plots similar to the one below
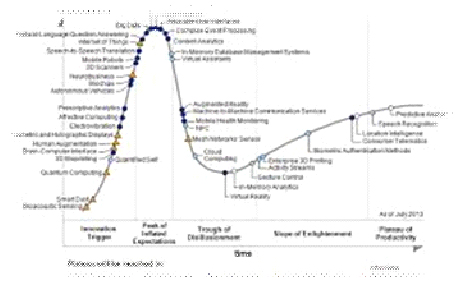
 With the rise of the smart phone, many people who have long seen themselves as non-gamers have began to download and play to occupy themselves throughout the day. If you're a game developer who has a history of writing your code in C#, then perhaps this still emerging market is something you should consider taking advantage of. This, however, will require the familiarization with other programming languages.
With the rise of the smart phone, many people who have long seen themselves as non-gamers have began to download and play to occupy themselves throughout the day. If you're a game developer who has a history of writing your code in C#, then perhaps this still emerging market is something you should consider taking advantage of. This, however, will require the familiarization with other programming languages.
One option for moving away from the C# language is to learn Java. Java is the programming used for apps on the android platform, billions of phones run on this programming language.
If you want to break into the android market, then learning Java is an absolute must.
There are both some pros and some cons to learning java. Firstly, if you already know C# or other languages and understand how they work, then java will be relatively easy to learn due to having similar, but quite simplified, syntax to C-based languages, the class library is large and standardized, but also very well written, and you might find that it will improve the performance and portability of your creations. Not to mention, learning java opens you up to the entirety of the android app and game market, a very large and still growing market that would otherwise stay closed off to you. That's too much ad and sale money to risk missing out on.
The few cons that come with learning the language is that, when coming from other languages, the syntax may take some getting used to. This is true for most languages. The other problem is that you must be careful with the specifics of how you write your code. While java can be written in a very streamlined fashion, it's also possible to write working, but bulky, code that will slow down your programs. Practice makes perfect, and the knowledge to avoid such pitfalls within the language.
If you wish to develop for the iOS on the other hand, knowledge of Objective C is required. The most compelling reason to learn Objective C is the market that it will open you up to. According to the website AndroidAuthority.com, in the article "Google play vs. Apple app store", users of iPhones and other iOS devices are much more likely to spend money on apps rather than downloading free ones.
Though learning Objective C might be a far jump from someone who currently writes in C#, it's certainly learn-able with a little bit of practice.
What are a few unique pieces of career advice that nobody ever mentions?
Good non-programmer jobs for people with software developer experience
Cloud computing is the recent rage in the IT industry. According to the report by Forbes, the estimated global market for cloud computing is expected to reach $35.6 billion in 2015, from the $12.1 billion market of 2010.
How it began
The idea of cloud computing was inspired by the concept of “utility computing” which introduced the idea of computing using the virtual servers. These virtual servers do not actually exist anywhere physically and can be moved anywhere without causing any disturbance to the end users. Thus it minimizes the cost involved on the devices to a great extent and provides innumerable benefits to the companies that adopt this system.
Cloud Computing Types
Tech Life in Idaho
| Company Name | City | Industry | Secondary Industry |
|---|---|---|---|
| Micron Technology, Inc. | Boise | Computers and Electronics | Semiconductor and Microchip Manufacturing |
| Boise Cascade Holdings | Boise | Manufacturing | Paper and Paper Products |
training details locations, tags and why hsg
The Hartmann Software Group understands these issues and addresses them and others during any training engagement. Although no IT educational institution can guarantee career or application development success, HSG can get you closer to your goals at a far faster rate than self paced learning and, arguably, than the competition. Here are the reasons why we are so successful at teaching:
- Learn from the experts.
- We have provided software development and other IT related training to many major corporations in Idaho since 2002.
- Our educators have years of consulting and training experience; moreover, we require each trainer to have cross-discipline expertise i.e. be Java and .NET experts so that you get a broad understanding of how industry wide experts work and think.
- Discover tips and tricks about Microsoft SQL Server programming
- Get your questions answered by easy to follow, organized Microsoft SQL Server experts
- Get up to speed with vital Microsoft SQL Server programming tools
- Save on travel expenses by learning right from your desk or home office. Enroll in an online instructor led class. Nearly all of our classes are offered in this way.
- Prepare to hit the ground running for a new job or a new position
- See the big picture and have the instructor fill in the gaps
- We teach with sophisticated learning tools and provide excellent supporting course material
- Books and course material are provided in advance
- Get a book of your choice from the HSG Store as a gift from us when you register for a class
- Gain a lot of practical skills in a short amount of time
- We teach what we know…software
- We care…